효율적인 데이터베이스 고가용성(HA) 구성 방법

F-Lab : 상위 1% 개발자들의 멘토링
AI가 제공하는 얕고 넓은 지식을 위한 짤막한 글입니다!
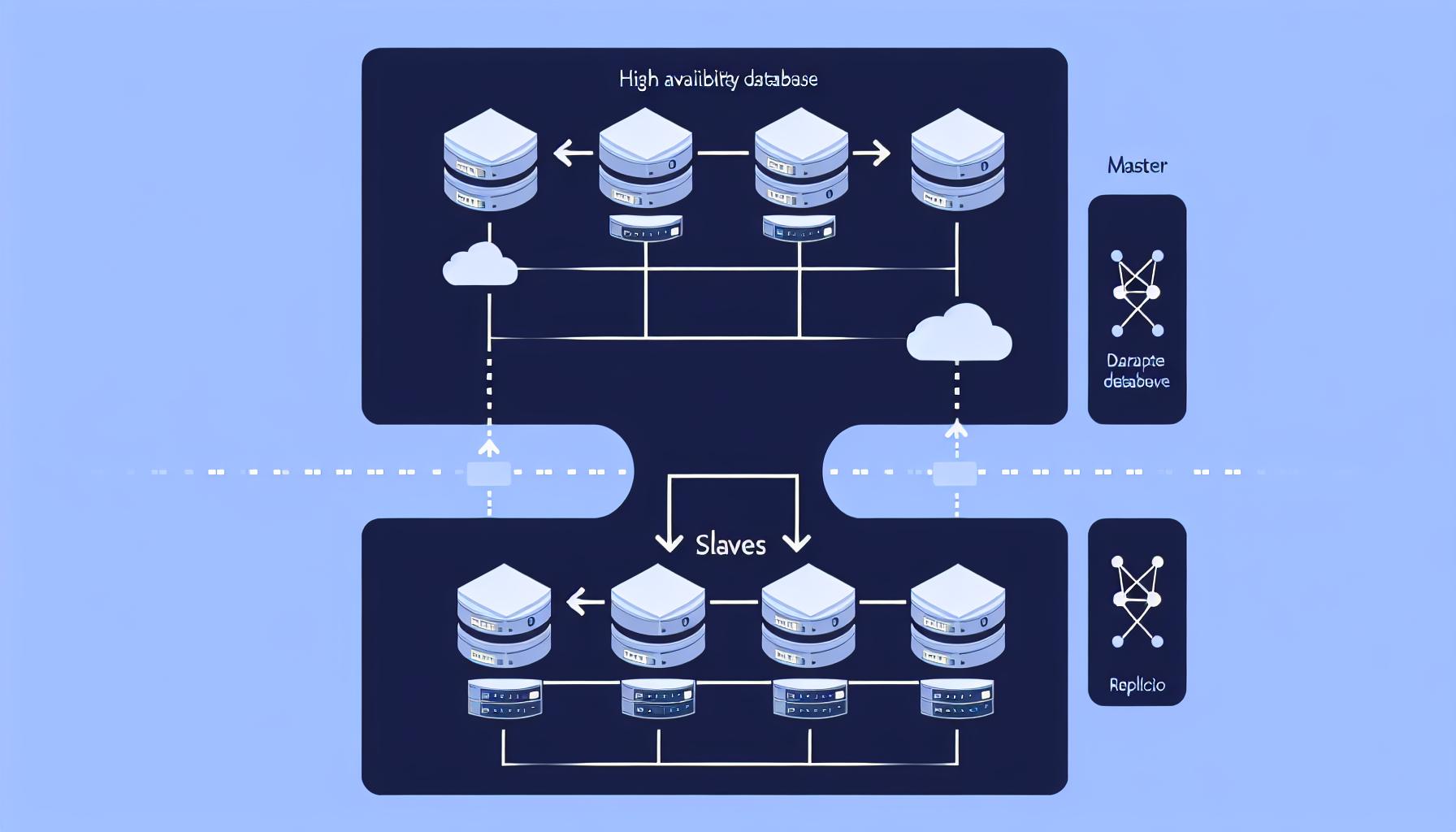
데이터베이스 고가용성의 중요성
현대의 웹 애플리케이션은 높은 트래픽과 데이터 처리 요구를 충족시키기 위해 고가용성(HA, High Availability)을 필수적으로 고려해야 합니다. 고가용성은 시스템이 장애 상황에서도 지속적으로 서비스를 제공할 수 있도록 설계하는 것을 의미합니다.
왜냐하면 데이터베이스는 애플리케이션의 핵심 요소로, 장애가 발생하면 전체 서비스가 중단될 수 있기 때문입니다. 따라서 데이터베이스의 고가용성은 시스템 안정성과 사용자 경험을 보장하는 데 중요한 역할을 합니다.
이 글에서는 데이터베이스 고가용성을 구현하는 다양한 방법과 기술을 살펴보고, 이를 통해 안정적인 시스템을 구축하는 방법을 알아보겠습니다.
특히 MySQL 리플리케이션과 NDB 클러스터를 활용한 고가용성 구성 방법에 대해 자세히 설명하겠습니다.
또한, Spring Framework를 활용한 데이터 소스 구성과 관련된 실질적인 예제도 함께 다룰 예정입니다.
MySQL 리플리케이션을 활용한 고가용성
MySQL 리플리케이션은 데이터베이스 고가용성을 구현하는 가장 일반적인 방법 중 하나입니다. 리플리케이션은 마스터 데이터베이스와 복제본 데이터베이스(Slave)를 구성하여 데이터를 복제하는 방식입니다.
왜냐하면 마스터 데이터베이스가 장애를 겪더라도 복제본 데이터베이스를 통해 읽기 작업을 지속할 수 있기 때문입니다. 이를 통해 시스템의 가용성을 높일 수 있습니다.
리플리케이션 설정은 다음과 같은 단계를 포함합니다:
# MySQL 리플리케이션 설정 예제
CHANGE MASTER TO
MASTER_HOST='master_host',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='log_file',
MASTER_LOG_POS=log_position;
START SLAVE;
이 방식은 읽기 작업을 복제본에서 처리하고, 쓰기 작업은 마스터에서 처리하는 구조로, 읽기 성능을 향상시킬 수 있습니다.
그러나 리플리케이션은 약간의 데이터 지연이 발생할 수 있으므로, 실시간 데이터 동기화가 필요한 경우에는 적합하지 않을 수 있습니다.
NDB 클러스터를 활용한 고가용성
NDB 클러스터는 MySQL의 고급 기능으로, 데이터베이스를 액티브-액티브(Active-Active) 구성으로 설정할 수 있습니다. 이를 통해 여러 대의 데이터베이스 서버가 동시에 데이터를 처리할 수 있습니다.
왜냐하면 NDB 클러스터는 데이터 분산 및 복제를 통해 데이터 손실을 방지하고, 높은 가용성을 제공하기 때문입니다. 이 방식은 특히 대규모 트래픽을 처리해야 하는 시스템에 적합합니다.
NDB 클러스터 설정은 복잡하지만, 데이터베이스의 안정성과 성능을 크게 향상시킬 수 있습니다. 다음은 NDB 클러스터 설정의 기본 예제입니다:
[mysqld]
ndbcluster
[ndbd]
DataDir=/var/lib/mysql-cluster
[ndb_mgmd]
DataDir=/var/lib/mysql-cluster
이 방식은 데이터베이스 서버 간의 동기화를 자동으로 처리하며, 장애 발생 시에도 데이터 손실 없이 서비스를 지속할 수 있습니다.
그러나 NDB 클러스터는 설정과 유지보수가 복잡하므로, 충분한 기술적 준비가 필요합니다.
Spring Framework를 활용한 데이터 소스 구성
Spring Framework는 데이터베이스 고가용성을 지원하는 다양한 기능을 제공합니다. 특히, 리플리케이션 데이터베이스를 활용한 데이터 소스 구성을 통해 읽기와 쓰기 작업을 분리할 수 있습니다.
왜냐하면 Spring Framework는 데이터 소스 설정을 통해 마스터와 복제본 데이터베이스 간의 작업을 자동으로 분배할 수 있기 때문입니다. 이를 통해 개발자는 별도의 로직 없이 효율적인 데이터베이스 작업을 수행할 수 있습니다.
다음은 Spring에서 리플리케이션 데이터 소스를 구성하는 예제입니다:
spring.datasource.url=jdbc:mysql:replication://master,slave1,slave2/db
spring.datasource.username=root
spring.datasource.password=password
이 설정을 통해 Spring은 자동으로 읽기 작업은 복제본에서, 쓰기 작업은 마스터에서 처리하도록 구성됩니다.
또한, Spring의 JPA와 QueryDSL을 활용하면 복잡한 쿼리도 효율적으로 작성할 수 있습니다.
고가용성 구성의 실제 사례와 경험
고가용성 구성은 이론뿐만 아니라 실제 경험이 중요합니다. 예를 들어, 대규모 트래픽을 처리하는 웹 애플리케이션에서 리플리케이션과 NDB 클러스터를 활용한 사례를 살펴보겠습니다.
왜냐하면 실제 사례를 통해 고가용성 구성의 장단점과 실질적인 문제 해결 방법을 이해할 수 있기 때문입니다. 예를 들어, 리플리케이션을 활용한 시스템에서 데이터 지연 문제가 발생했을 때, 이를 해결하기 위해 캐싱을 도입한 사례가 있습니다.
또한, NDB 클러스터를 활용한 시스템에서는 데이터 분산으로 인해 발생하는 네트워크 지연 문제를 해결하기 위해 로드 밸런서를 도입한 사례도 있습니다.
이러한 경험은 고가용성 시스템을 설계하고 구현하는 데 있어 중요한 참고 자료가 됩니다.
따라서, 고가용성 구성에 대한 이론과 실제 경험을 결합하여 안정적이고 효율적인 시스템을 구축할 수 있습니다.
결론: 고가용성 구성의 핵심
데이터베이스 고가용성은 현대 웹 애플리케이션에서 필수적인 요소입니다. 이를 구현하기 위해 MySQL 리플리케이션, NDB 클러스터, Spring Framework와 같은 다양한 기술을 활용할 수 있습니다.
왜냐하면 이러한 기술들은 데이터 손실을 방지하고, 시스템의 안정성과 성능을 향상시키는 데 효과적이기 때문입니다. 특히, 리플리케이션과 NDB 클러스터는 각각의 장단점이 있으므로, 시스템 요구사항에 따라 적절히 선택해야 합니다.
또한, Spring Framework를 활용한 데이터 소스 구성은 개발자의 작업을 간소화하고, 효율적인 데이터베이스 작업을 가능하게 합니다.
결론적으로, 데이터베이스 고가용성은 시스템의 안정성과 사용자 경험을 보장하는 데 중요한 역할을 합니다. 이를 위해 다양한 기술과 경험을 결합하여 최적의 솔루션을 설계해야 합니다.
이 글이 데이터베이스 고가용성을 구현하는 데 있어 유용한 참고 자료가 되기를 바랍니다.
이 컨텐츠는 F-Lab의 고유 자산으로 상업적인 목적의 복사 및 배포를 금합니다.




