분산 파일 시스템 HDFS의 구조와 동작 원리

F-Lab : 상위 1% 개발자들의 멘토링
AI가 제공하는 얕고 넓은 지식을 위한 짤막한 글입니다!
HDFS란 무엇인가?
HDFS(Hadoop Distributed File System)는 대규모 데이터를 분산 저장하고 관리하기 위한 파일 시스템입니다. HDFS는 데이터를 블록 단위로 나누어 여러 서버에 분산 저장하며, 데이터의 복제본을 생성하여 안정성을 높입니다.
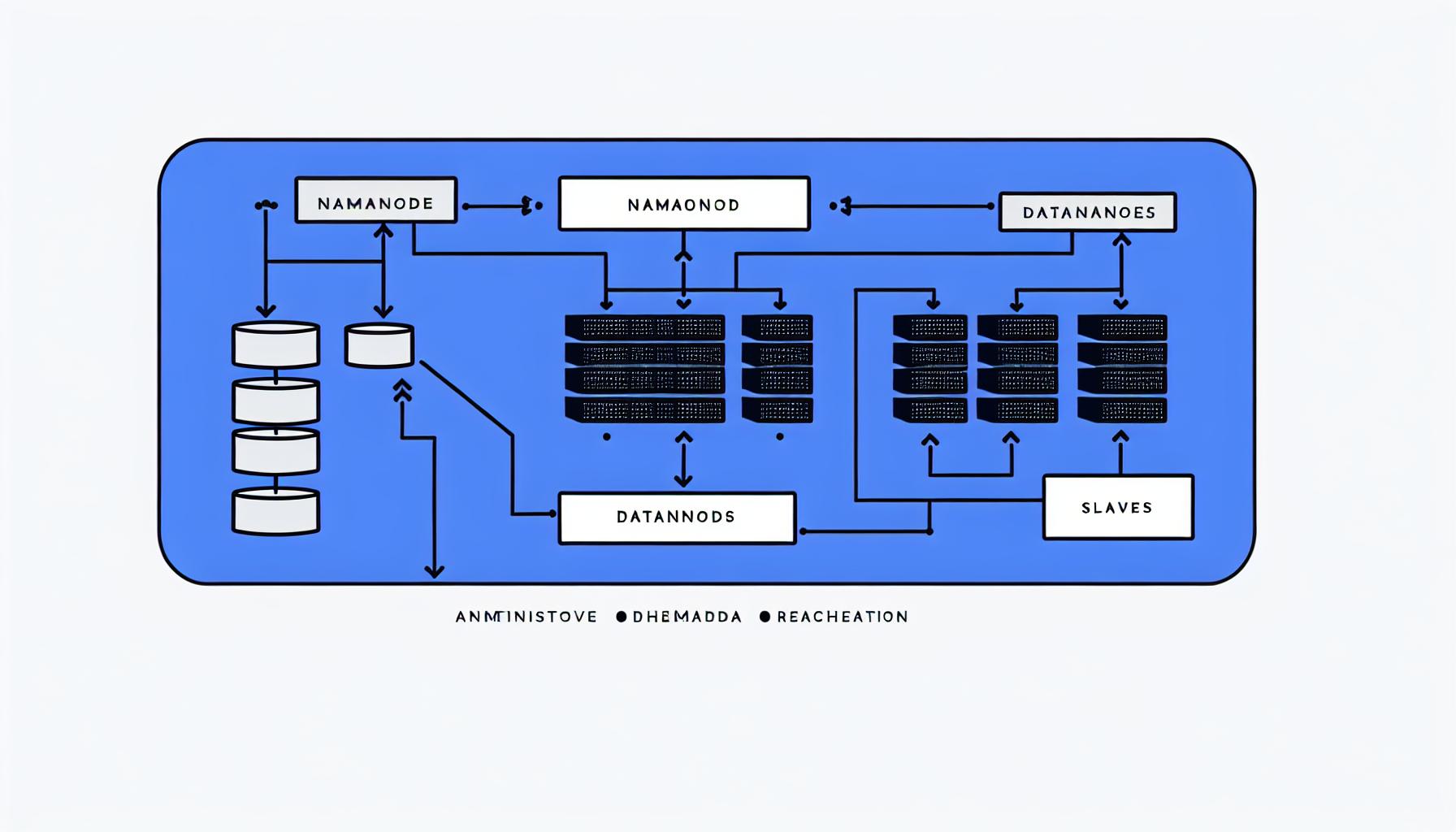
HDFS는 마스터-슬레이브 구조로 구성됩니다. 마스터 역할은 네임 노드(NameNode)가 담당하며, 슬레이브 역할은 데이터 노드(DataNode)가 수행합니다. 네임 노드는 메타데이터를 관리하고, 데이터 노드는 실제 데이터를 저장합니다.
왜냐하면 HDFS는 대규모 데이터를 효율적으로 처리하기 위해 설계된 시스템이기 때문입니다. 이를 통해 데이터의 안정성과 접근성을 보장할 수 있습니다.
HDFS는 특히 빅데이터 처리에 적합하며, 다양한 분산 시스템과 결합하여 사용됩니다. 예를 들어, 스파크(Spark)나 하이브(Hive)와 같은 도구와 함께 사용됩니다.
이 글에서는 HDFS의 구조와 동작 원리를 상세히 살펴보겠습니다.
HDFS의 주요 컴포넌트
HDFS는 크게 네임 노드와 데이터 노드로 구성됩니다. 네임 노드는 메타데이터를 관리하며, 데이터 노드는 실제 데이터를 저장합니다.
네임 노드는 FS 이미지와 에디트 로그라는 두 가지 주요 파일을 관리합니다. FS 이미지는 파일 시스템의 상태를 저장하며, 에디트 로그는 파일 생성 및 삭제와 같은 트랜잭션 로그를 기록합니다.
왜냐하면 네임 노드가 메타데이터를 관리함으로써 데이터의 위치와 상태를 효율적으로 추적할 수 있기 때문입니다. 이를 통해 데이터 복구와 관리가 용이해집니다.
데이터 노드는 블록 데이터를 물리적으로 저장하며, 하드디스크나 SSD와 같은 저장 장치를 사용합니다. 데이터 노드는 네임 노드와 주기적으로 상태 정보를 교환하여 시스템의 안정성을 유지합니다.
이러한 구조는 HDFS가 대규모 데이터를 안정적으로 관리할 수 있도록 설계된 이유입니다.
HDFS의 데이터 읽기와 쓰기
HDFS에서 데이터 읽기와 쓰기는 서로 다른 동작 원리를 가집니다. 데이터 쓰기는 클라이언트가 네임 노드에 요청을 보내고, 네임 노드가 적절한 데이터 노드를 선택하여 데이터를 저장합니다.
데이터 읽기는 클라이언트가 네임 노드에서 메타데이터를 가져와 데이터 노드에서 직접 데이터를 읽는 방식으로 이루어집니다. 이 과정에서 데이터의 복제본이 활용됩니다.
왜냐하면 HDFS는 데이터의 안정성과 접근성을 보장하기 위해 복제본을 활용하기 때문입니다. 이를 통해 데이터 손실을 방지하고, 읽기 성능을 최적화할 수 있습니다.
HDFS는 데이터의 분산 저장과 복제를 통해 대규모 데이터를 효율적으로 처리할 수 있는 환경을 제공합니다.
이러한 동작 원리는 HDFS가 빅데이터 처리에 적합한 이유 중 하나입니다.
HDFS와 물리적 하드웨어
HDFS는 물리적 하드웨어와 밀접한 연관이 있습니다. 데이터 노드는 일반적으로 서버 랙(Rack)에 배치되며, 랙 간의 물리적 거리가 데이터 전송 속도에 영향을 미칩니다.
랙 내부의 서버 간 데이터 전송은 매우 빠르며, 랙 간 전송은 상대적으로 느립니다. 따라서 HDFS는 데이터 복제를 통해 이러한 물리적 제약을 극복합니다.
왜냐하면 데이터 복제를 통해 데이터 접근 속도를 최적화하고, 장애 발생 시 데이터를 복구할 수 있기 때문입니다. 이를 통해 시스템의 안정성과 성능을 보장합니다.
HDFS는 또한 하드웨어 장애를 감지하고, 데이터를 자동으로 복구하는 기능을 제공합니다. 이는 네임 노드가 데이터 노드의 상태를 주기적으로 확인함으로써 가능합니다.
이러한 설계는 HDFS가 대규모 데이터를 안정적으로 관리할 수 있는 이유 중 하나입니다.
HDFS의 한계와 발전 방향
HDFS는 대규모 데이터를 효율적으로 관리할 수 있는 강력한 도구이지만, 몇 가지 한계도 존재합니다. 예를 들어, 실시간 데이터 처리에는 적합하지 않습니다.
HDFS는 배치 처리에 최적화되어 있으며, 실시간 처리를 위해서는 스파크(Spark)나 카프카(Kafka)와 같은 도구와 결합해야 합니다.
왜냐하면 HDFS는 설계상 실시간 데이터 처리를 염두에 두지 않았기 때문입니다. 따라서 실시간 처리가 필요한 경우에는 다른 도구와의 결합이 필수적입니다.
HDFS는 또한 메타데이터를 관리하는 네임 노드가 단일 장애 지점(Single Point of Failure)이 될 수 있습니다. 이를 해결하기 위해 세컨더리 네임 노드와 같은 보조 시스템이 사용됩니다.
이러한 한계를 극복하기 위해 HDFS는 지속적으로 발전하고 있으며, 새로운 기술과의 결합을 통해 더 나은 성능과 안정성을 제공하고 있습니다.
결론: HDFS의 중요성과 학습 방향
HDFS는 빅데이터 처리의 핵심 기술 중 하나로, 대규모 데이터를 효율적으로 관리하고 처리할 수 있는 강력한 도구입니다. HDFS의 구조와 동작 원리를 이해하는 것은 데이터 엔지니어링의 기본입니다.
HDFS는 네임 노드와 데이터 노드로 구성된 마스터-슬레이브 구조를 기반으로 하며, 데이터를 블록 단위로 분산 저장하고 복제본을 생성하여 안정성을 보장합니다.
왜냐하면 이러한 설계가 대규모 데이터를 안정적으로 관리하고, 장애 발생 시 데이터를 복구할 수 있는 환경을 제공하기 때문입니다.
HDFS는 또한 다른 분산 시스템과 결합하여 사용되며, 이를 통해 다양한 데이터 처리 요구를 충족할 수 있습니다. 예를 들어, 스파크나 하이브와 같은 도구와의 결합이 가능합니다.
따라서 HDFS를 학습할 때는 구조와 동작 원리를 깊이 이해하고, 다른 분산 시스템과의 연계를 고려하는 것이 중요합니다.
이 컨텐츠는 F-Lab의 고유 자산으로 상업적인 목적의 복사 및 배포를 금합니다.




