실시간 데이터 처리 시스템 설계와 구현

F-Lab : 상위 1% 개발자들의 멘토링
AI가 제공하는 얕고 넓은 지식을 위한 짤막한 글입니다!
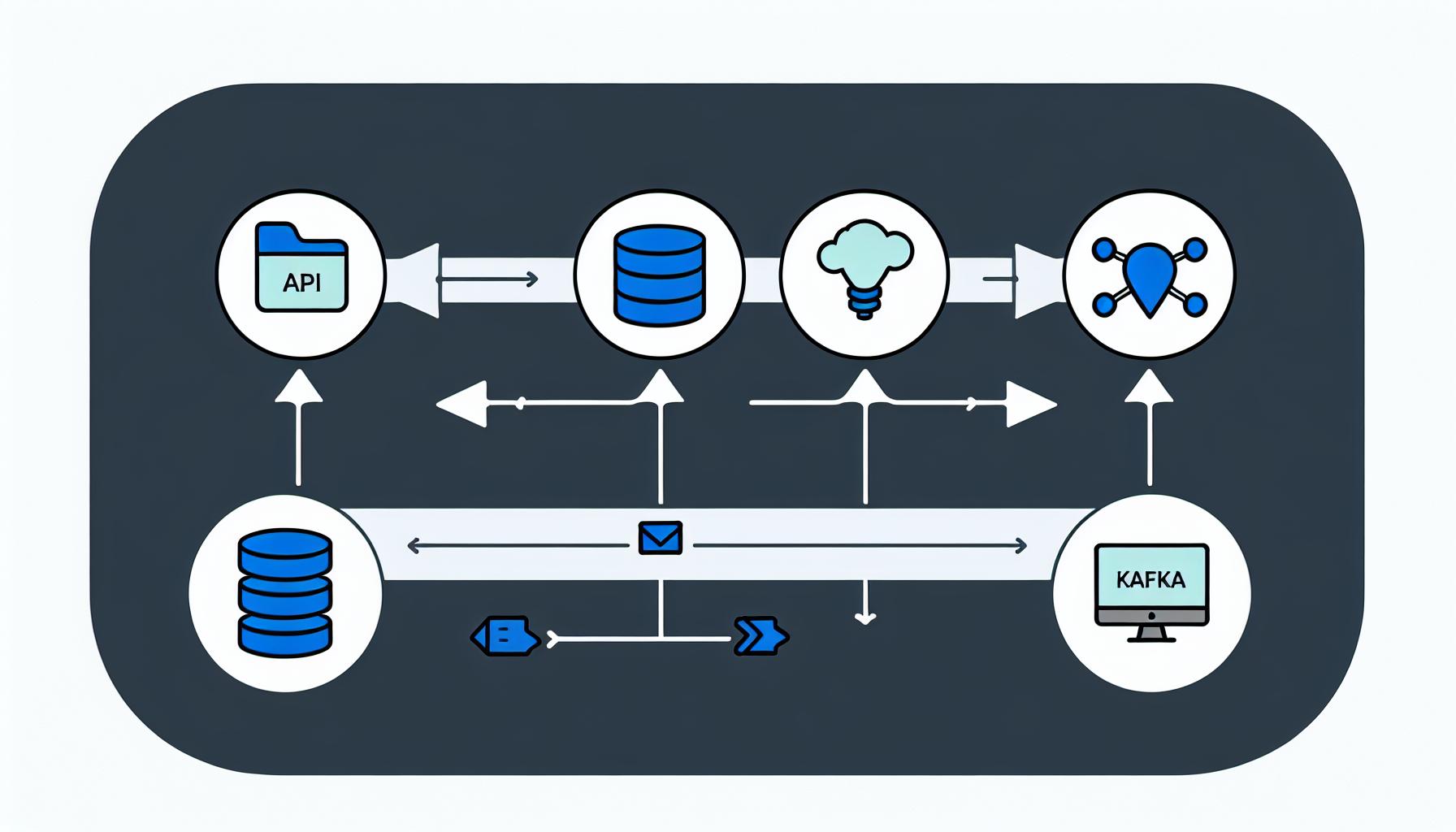
실시간 데이터 처리의 중요성
실시간 데이터 처리는 현대의 다양한 산업에서 필수적인 요소로 자리 잡고 있습니다. 특히 금융, 이커머스, 그리고 대규모 트랜잭션이 발생하는 시스템에서는 실시간 데이터 처리가 핵심적인 역할을 합니다.
왜냐하면 실시간 데이터 처리는 사용자 경험을 향상시키고, 빠른 의사결정을 가능하게 하며, 시스템의 효율성을 극대화하기 때문입니다.
이 글에서는 실시간 데이터 처리 시스템을 설계하고 구현하는 방법에 대해 다룹니다. 특히, 이벤트 스트리밍 서버와 비동기 폴링, 큐잉 시스템을 활용한 아키텍처 설계에 초점을 맞춥니다.
실시간 데이터 처리 시스템은 단순히 데이터를 수집하는 것을 넘어, 데이터를 효율적으로 저장하고 처리하며, 필요한 곳에 적시에 전달하는 것을 목표로 합니다.
따라서, 이러한 시스템을 설계하기 위해서는 다양한 기술과 이론을 이해하고, 이를 실제로 구현할 수 있는 능력이 필요합니다.
실시간 데이터 처리 시스템의 기본 아키텍처
실시간 데이터 처리 시스템의 기본 아키텍처는 크게 데이터 수집, 데이터 버퍼링, 데이터 소비의 세 가지 단계로 나뉩니다.
왜냐하면 데이터 수집 단계에서는 외부 API나 웹소켓을 통해 데이터를 가져오고, 데이터 버퍼링 단계에서는 큐잉 시스템을 통해 데이터를 임시 저장하며, 데이터 소비 단계에서는 데이터를 처리하고 저장하기 때문입니다.
예를 들어, Kafka와 같은 이벤트 스트리밍 서버를 사용하면 대규모 데이터의 실시간 처리가 가능합니다. Kafka는 데이터를 프로듀서에서 브로커로 전달하고, 브로커는 데이터를 컨슈머에게 전달하는 구조를 가지고 있습니다.
또한, SQS와 같은 간단한 큐잉 시스템을 사용하여 데이터의 유실을 방지하고, 시스템의 안정성을 높일 수 있습니다.
이러한 아키텍처는 다양한 산업에서 활용될 수 있으며, 특히 금융과 같은 실시간성이 중요한 분야에서 필수적입니다.
비동기 폴링과 큐잉 시스템의 활용
비동기 폴링은 실시간 데이터 처리 시스템에서 중요한 역할을 합니다. 이는 데이터를 주기적으로 확인하고, 필요한 데이터를 가져오는 방식입니다.
왜냐하면 비동기 폴링은 시스템의 부하를 줄이고, 데이터를 효율적으로 처리할 수 있게 하기 때문입니다.
예를 들어, 웹소켓을 사용하여 실시간 데이터를 스트리밍하거나, REST API를 주기적으로 호출하여 데이터를 가져오는 방식이 있습니다.
큐잉 시스템은 데이터를 임시로 저장하고, 데이터를 처리할 준비가 되었을 때 소비할 수 있도록 합니다. Kafka, RabbitMQ, SQS와 같은 큐잉 시스템은 이러한 역할을 수행합니다.
큐잉 시스템을 활용하면 데이터의 유실을 방지하고, 시스템의 안정성을 높일 수 있습니다. 또한, 데이터 처리 속도를 조절하여 시스템의 성능을 최적화할 수 있습니다.
실시간 데이터 처리 시스템의 구현
실시간 데이터 처리 시스템을 구현하기 위해서는 다양한 기술과 도구를 활용해야 합니다. 예를 들어, Kafka를 사용하여 데이터를 스트리밍하고, SQS를 사용하여 데이터를 큐잉할 수 있습니다.
왜냐하면 이러한 도구들은 대규모 데이터를 효율적으로 처리하고, 시스템의 안정성을 높이는 데 도움을 주기 때문입니다.
아래는 Kafka를 사용하여 데이터를 스트리밍하는 간단한 예제입니다:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('topic_name', b'Sample Message')
producer.close()
이와 같이, Kafka를 사용하여 데이터를 스트리밍하고, 컨슈머를 통해 데이터를 처리할 수 있습니다.
또한, SQS를 사용하여 데이터를 큐잉하고, 데이터를 소비하는 애플리케이션을 구현할 수 있습니다. 이러한 구현은 시스템의 요구사항에 따라 다양하게 변경될 수 있습니다.
실시간 데이터 처리 시스템의 최적화
실시간 데이터 처리 시스템을 최적화하기 위해서는 다양한 요소를 고려해야 합니다. 예를 들어, 데이터 처리 속도를 높이기 위해 큐잉 시스템의 설정을 조정하거나, 데이터 유실을 방지하기 위해 트랜잭션을 활용할 수 있습니다.
왜냐하면 시스템의 성능과 안정성을 높이기 위해서는 이러한 최적화 작업이 필수적이기 때문입니다.
또한, 시스템의 모니터링과 로깅을 통해 문제를 사전에 발견하고, 이를 해결할 수 있는 방안을 마련해야 합니다.
예를 들어, ELK 스택을 사용하여 시스템의 로그를 분석하고, 문제를 사전에 발견할 수 있습니다. ELK 스택은 Elasticsearch, Logstash, Kibana로 구성된 로그 분석 도구입니다.
이와 같이, 실시간 데이터 처리 시스템을 최적화하기 위해서는 다양한 기술과 도구를 활용해야 합니다. 이를 통해 시스템의 성능과 안정성을 높일 수 있습니다.
결론: 실시간 데이터 처리 시스템의 미래
실시간 데이터 처리 시스템은 현대의 다양한 산업에서 필수적인 요소로 자리 잡고 있습니다. 특히, 금융, 이커머스, 그리고 대규모 트랜잭션이 발생하는 시스템에서는 실시간 데이터 처리가 핵심적인 역할을 합니다.
왜냐하면 실시간 데이터 처리는 사용자 경험을 향상시키고, 빠른 의사결정을 가능하게 하며, 시스템의 효율성을 극대화하기 때문입니다.
이 글에서는 실시간 데이터 처리 시스템을 설계하고 구현하는 방법에 대해 다루었습니다. 특히, 이벤트 스트리밍 서버와 비동기 폴링, 큐잉 시스템을 활용한 아키텍처 설계에 초점을 맞췄습니다.
실시간 데이터 처리 시스템은 단순히 데이터를 수집하는 것을 넘어, 데이터를 효율적으로 저장하고 처리하며, 필요한 곳에 적시에 전달하는 것을 목표로 합니다.
따라서, 이러한 시스템을 설계하기 위해서는 다양한 기술과 이론을 이해하고, 이를 실제로 구현할 수 있는 능력이 필요합니다.
이 컨텐츠는 F-Lab의 고유 자산으로 상업적인 목적의 복사 및 배포를 금합니다.




